As recently published on our website, the Teutonic Knights Bible has now been made available in a digitally reconstructed form. As explained in full in that article – and very briefly recapped here – this 14th-century three volume manuscript had been broken up, with the first volume now lost, the third volume held in full at Keble College, Oxford, and fragments and leaves of the second volumes held at the V&A and the British Library.
We set out to create a digital reconstruction using the IIIF standards to re-unite as many of these pages as we could, as we knew we could use the British Libraries’ IIIF service to incorporate their pages into a reconstruction of the second volume. However as there would still be some missing pages, we needed to ensure the reconstruction we built also clearly indicated these missing sections, in order to not give a false impression of a complete manuscript.
Building manuscript reconstructions
We know that IIIF provides us with a standard way to describe to compatible viewing software (such as Universal Viewer, Mirador, Canvas Panel, etc) how it should present a sequence of images, enabling it to present digitally a reconstructed book, scroll, painting, and indeed a manuscript. The IIIF manifest is a JSON data structure which lists the images that should be shown, the order for them to be shown in, their associated metadata, annotations and more complex sequences (e.g. chapters). Viewing software reads in this manifest, retrieves the relevant images (using the IIIF Image API, which allows images to be requested at an appropriate size and enable deep-zoom functionality) and presents them to the user in the correct order. Some of the objects we are already showing on our site using this approach are:
- Devonshire Hunting Tapestries
- Raphael Cartoons
- Entartete Kunst
- Leonardo da Vinci’s Notebooks (Codex Forster I, II, III)
- Playfair Book of Hours
But how do you create these manifests? For an object with a single image (a tapestry for example) this is a relatively simple thing to do as we already have our collections’ metadata we can use about the object which lists the object images available. With a simple Python script (using the Prezi library) we can convert this data into a IIIF manifest.

But for complex objects such as manuscripts we also need to be able to do things such as:
- Put the images in an order to indicate the pages of the book (including possibly the bindings, fold-outs, etc)
- Possibly also provide an alternative order if there are different opinions about the original physical sequence
- Indicate any missing pages/sections now lost
- Incorporate images from another institution with their own IIIF image server and manifest for their digitised manuscript
- Store xywh (x,y, width, height) image crop co-ordinates to remove any unneeded background from the image
- Group pages into (named) sections to provide a table of contents where relevant (e.g. chapters, volumes)
- Provide object metadata describing the overall physical object (and ideally metadata per page)
- And other features we or IIIF viewers do not support yet, such as showing annotated areas on each page
To construct all of this we need to have some data source(s) to build from that capture the above requirements. Combining these together programmatically we can transform the data into the IIIF manifest. It might seem that, given the IIIF manifest itself can obviously record all this information, we should just use that as the source record we create and maintain. This may be a consideration, but the downsides to that approach are:
- There is no application to fully store and edit generated IIIF manifests beyond basic sequencing
- None of the museum systems that manage collection data natively understand IIIF manifests (at present), so all the knowledge contained in them would be isolated from the IIIF management system.
- The IIIF data structure is designed to serve the purpose of presenting digital objects and not to be a catch-all storage solution for all cultural heritage metadata, tempting as it may be.
So, at present, we need to create our IIIF manifests from our existing knowledge management systems using some other approach.
Manifest building – current approach
Each digital reconstruction we have built has been increasingly more complex. For all of these reconstructions, we have gradually evolved a YAML based configuration file describing the original object which provides:
- Overall object metadata (title, description, object identifier)
- Presentation options (e.g. should this be shown as a book, should it have a table of contents, etc)
- List of images in sequence and their captions/titles
- Grouping of images to be shown as sections
- Ability to indicate missing pages/sections
And a different version of the simple Prezi-based Python script mentioned earlier (which handled just a single image) has ‘evolved’ over time to read in this YAML file and from this generate the more complex IIIF manifest. For example, for the Teutonic Knights bible reconstruction:
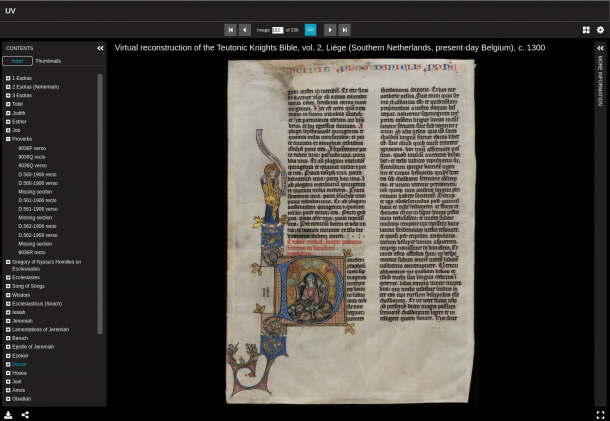
title: "Virtual reconstruction of the Teutonic Knights Bible, vol. 2, Liège (Southern Netherlands, present-day Belgium), c. 1300"
description: "This Bible was originally made of three volumes. Volume 1, containing the beginning of the Old Testament, has not survived. Volume 3, containing the New Testament, is still extant and kept at Keble College Library in Oxford. Volume 2, which contained the end of the Old Testament, was taken apart, probably in the 19th century, and most of its surviving leaves are now in the V&A collection with some also at the British Library (designated in the Index as BL). What you see here is a IIIF reconstruction of this now lost volume, bringing together pieces in the V&A and at the BL."
summary: ""
object: manuscript-individuals
source: "Handcoded by Richard Palmer (from Catherine's spreadsheet, 2022-2023)"
identifier: "DM02"
reconstruction:
-
source: BL
manifest: https://api.bl.uk/metadata/iiif/ark:/8105 /vdc_100149251954.0x000001/manifest.json
options:
flatten_montage: True
full_toc: True
folios:
-
label: "BL, Add. 32058, f. 9r"
source: BL
image: BL0001
match: "f. 9r"
-
label: "BL, Add. 32058, f. 9v"
source: BL
image: BL0002
match: "f. 9v"
-
label: "Missing section"
image: EMPTY01
-
label: "D.589-1906 recto"
image: 2021MY4172
[...]
This configuration file lets us make simple changes to the reconstruction such as a page title change, an image ordering change etc. by editing the file and re-running our Python script which reads it in to generate the IIIF manifest.

So, all problems solved ? Well, not really, because the terrible truth behind the YAML file is that it is mostly manually created and maintained, based on that worst of all data management crimes: spreadsheets through email. Yes, ‘manuscript-final_final_typos-corrected_try-this-one’ is passed back and forth between ourselves and a curator as we try to create in digital form something that no longer exists in a unified physical form. This lack of existence in the physical world can make what would otherwise be a trivial change hard to communicate. Even identifying and communicating the relevant page to make a change too can be complicated and often the easiest approach is to have a video call to explain the change.
It should also be pointed out that neither the spreadsheets nor the YAML file can be stored in any actionable way in the knowledge management systems used to maintain the museums collections data. So all of this intellectual work establishing a reconstructions’ sequences, captions, sections, annotations etc, exists solely within non-standard files formats and systems that have no permanent data management.
Future improvements
This current production process is one we would obviously like to change, and we think others might have the same issues (or perhaps they have a much better process they may want to share!), so we would be very keen to talk with colleagues facing the same challenges. We think the main issues to be resolved are:
- Creating a data model to describe manuscripts. These in particular present the most complex reconstruction challenge (hence their role in the establishment of IIIF as a standard). There is much work already done here on different aspects of manuscript modelling e.g. Viscoll, Mapping Manuscript Migrations. This is not a new idea and we recognise it’s not a simple task to capture the rich history of manuscripts. We would look to the Linked Art pragmatic approach of trying to solve 90% of the data modelling problems for reconstructions and not get too bogged down in trying to create the perfect data model for the history of a manuscript.
- Developing agreed identifiers for digital reconstructions, to indicate these are not objects in the museum collection but reconstructions that may be combining content from across multiple cultural heritage collections
- Implementing this data model in an open source application(s) – allowing the creation of a IIIF manifest describing a manuscript by domain experts (not requiring software developers typing into cryptic configuration files)
- Incorporating parts of the data model that are widely applicable for other cultural heritage objects into existing cultural heritage systems such as DAMS/Collections Management System. This is where we could see a solution to problems that are common across cultural heritage object types (as museum systems can rarely afford to be dedicated to managing data for one single type of object) such as image sequencing, annotating, etc
- A dedicated system/platform for aggregating manuscript reconstructions. This may be beyond the interests of a single cultural heritage institution and instead more of a challenge for the sector to come together nationally, as seen with Biblissima for French manuscripts, Handschriftenportal for German manuscripts, etc.
We hope some of these issues will be discussed at the upcoming IIIF conference and in the future manuscript reconstructions, however complex the object, will become a little simpler to generate.


